Top 10 DuckDB Extensions to Tell Your Spouse About

Sometimes you just run out of things to talk about on a long road trip. Luckily there’s always DuckDB: a game-changing in-process database—capable of querying data from just about anywhere (local files, cloud storage, you name it) with no ETL. When you combine that power with the right extensions, the possibilities are endless.
I’ve been building with DuckDB for a few years and have seen the ecosystem evolve firsthand. This list is my personal take on the most popular, actively maintained DuckDB extensions out there. So, if you need some lighthearted conversation fodder for your next date night, don’t worry—I got you!
Iceberg
Stars: 225 | Maintainer: DuckDB Team | INSTALL iceberg; LOAD iceberg;
If you’ve read our post on Iceberg and Serverless DuckDB in Google Cloud, you’ll know that this extension makes it fairly easy to build a "Pretty Good and Cheap Data Lake™”. We’ve even used Iceberg with DuckDB at Definite to make a pretty damn good data lake.
Delta Lake
Stars: 168 | Maintainer: DuckDB Team | INSTALL delta; LOAD delta;
Like Iceberg, Delta Lake brings big data table management to your DuckDB workflows—but with a stronger emphasis on transactional consistency. If you’re coming from the Databricks ecosystem or already have Delta tables sitting in cloud storage, this extension lets you query them directly from DuckDB without any heavy lifting. Delta Lake maintains an append-only transaction log that allows for time travel queries and ACID compliance which is great if you’re working with streaming data pipelines or just want to peek at how your dataset looked last week.
Google Sheets (GSheets)
Stars: 240 | Maintainer: Community (Evidence.dev) | INSTALL gsheets; LOAD gsheets;
If your operations team’s unofficial motto is “It’s in a Google Sheet somewhere”, then this extension is for you. The GSheets extension lets you read and write directly to Google Sheets using SQL queries inside DuckDB—no need to export to CSV first or, god forbid, wrestle with Google Apps Script. Whether you're using a Google Sheet as a real-time lookup table or the sales team treats Sheets like a masochist’s relational database, this extension makes it feel like any other SQL table. Archie did us all a solid with this one.
Geospatial (Spatial)
Stars: 532 | Maintainer: DuckDB Team | INSTALL spatial; LOAD spatial;
tl;dr: Your favorite spatial queries without spinning up a full-fledged GIS system. The Geospatial (Spatial) extension lets you do just that. Whether you’re working with points, polygons, distances, or intersections, this extension brings PostGIS-like functionality to DuckDB—except it's lightweight and blazingly fast. If your dataset includes coordinates, routes, or regional boundaries, you can now analyze and visualize spatial data natively inside DuckDB.
Know what will impress your SO? Bounding box queries from memory. Have you ever tried??
PRQL
Stars: 279 | Maintainer: ywelsch | INSTALL prql; LOAD prql;
SQL if writing feels order out of sometimes. Or translated to PRQL: if writing SQL sometimes feels out order then PRQL might be your new best friend. The PRQL extension lets you write queries in a more readable, composable way, which then compiles down to SQL under the hood. Think of it as DuckDB’s answer to dbt’s SQL simplification, allowing you to build declarative, pipeline-style queries without getting tangled in subqueries and joins. If you've ever found yourself writing the same SELECT … FROM (SELECT … FROM …) nonsense over and over, PRQL might just save your sanity.
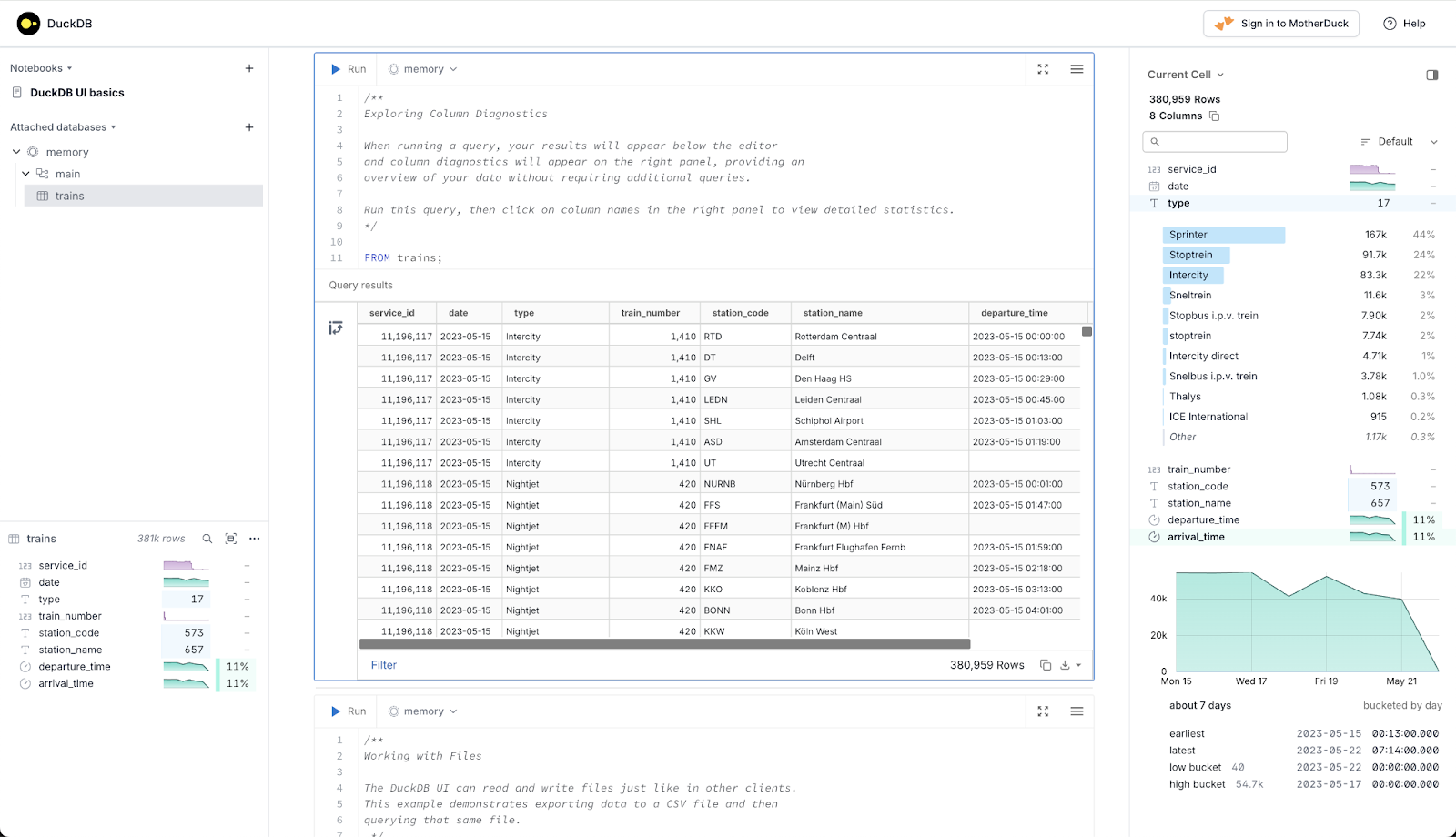
DuckDB UI
Stars: 52 | Maintainer: DuckDB Team | INSTALL ui; LOAD ui;
The command line isn’t for everybody. But DuckDB UI is. Built by the team at MotherDuck, this extension gives you a web-based interface for running DuckDB queries that you can think of as pgAdmin for DuckDB. Whether you’re introducing someone to DuckDB for the first time or just want a more pleasant SQL experience, this UI extension makes your DuckDB workflow just a little more comfy.
PostgreSQL
Stars: 272 | Maintainer: DuckDB Team | INSTALL postgres; LOAD postgres;
A seamless mix of DuckDB's speed with PostgreSQL’s robustness, the PostgreSQL extension lets DuckDB query Postgres databases directly—without needing to export data or use an intermediary tool. This means you can join a local Parquet file with a live Postgres table, analyze massive datasets without moving them around, and bring DuckDB’s columnar speed into your existing Postgres workflows. Think of it as a lightweight analytical turbo boost for your favorite relational database.
Vector Similarity (VSS)
Stars: 128 | Maintainer: DuckDB Team | INSTALL vss; LOAD vss;
VSS brings approximate nearest neighbor (ANN) search to DuckDB, meaning you can efficiently find similar items without scanning an entire dataset. Whether you're working on recommendation systems, AI-powered search, or clustering models, this extension lets you query embeddings with SQL—all without needing a separate vector database. Go ahead: change your website’s TLD to .ai.
Apache Arrow
Stars: 38 | Maintainer: DuckDB Team | INSTALL arrow; LOAD arrow;
If you love Apache Arrow for its fast in-memory columnar format, you’ll be happy to know that DuckDB does too. The Arrow extension enables zero-copy integration, meaning DuckDB can query Arrow data directly without wasting time on conversion or duplication. Whether you’re working with PyArrow tables, interoperating with other Arrow-native tools, or just want to squeeze the most performance out of your analytics workflow, this extension makes sure your data stays fast and efficient.
HTTP Server
Stars: 165 | Maintainer: Community | INSTALL httpfs; LOAD httpfs;
“Now you can now have DuckDB instances query each other and... themselves!” The HTTP server extension makes it possible to spin up a REST API that exposes DuckDB queries over HTTP, making it easy to integrate with web apps, dashboards, or even other microservices. No need for a heavy database server—just start DuckDB, enable the extension, and you’ve got a serverless analytics backend on demand. Perfect for when you want to query DuckDB remotely without dealing with database drivers.
Honorable mention: Crabwalk
Crabwalk is not exactly an extension, but it will still make your spouse perk up their ears. It's a lightweight SQL orchestration tool built on top of DuckDB. It processes SQL files in a folder, determines dependencies, and executes them in the correct order. Features include flexible output types (tables, views, or files like Parquet, CSV, JSON), model-level configuration using SQL comments, schema generation, column-level lineage tracking, schema visualization, optional S3 integration for backups, minimal dependencies, and support for environment variables in SQL queries.
Stop reading, start installing
With these extensions, DuckDB goes from a fun little side project to a production powerhouse. Whether you’re spinning up a serverless analytics backend, querying Iceberg tables, or just avoiding spreadsheets at all costs, there’s something here for everyone.
Install a few, break some data, and if you want to add one or talk about it with somebody who cares: @thisritchie.