Understanding smallpond and 3FS: A Clear Guide

I didn't have "DeepSeek releases distributed DuckDB" on my 2025 bingo card.
You may have stumbled across smallpond from Twitter/X/LinkedIn hype. From that hype, you might have concluded Databricks and Snowflake are dead 😂. Not so fast. The reality is, although this is interesting and powerful open source tech, it's unlikely to be widely used in analytics anytime soon. Here's a concise breakdown to help you cut through the noise.
We'll cover:
- what
smallpondand its companion,3FS, are - if they're suitable for your use case and if so
- how you can use them
What is smallpond?
smallpond is a lightweight, distributed data processing framework recently introduced by DeepSeek. It extends DuckDB (typically a single-node analytics database) to handle larger datasets across multiple nodes. smallpond enables DuckDB to manage distributed workloads by using a distributed storage and compute system.
Key features:
- Distributed Analytics: Allows DuckDB to handle larger-than-memory datasets by partitioning data and running analytics tasks in parallel.
- Open Source Deployment: If you can manage to get it running, 3FS would give you powerful and performant storage at a fraction of the cost of alternatives.
- Manual Partitioning: Data is manually partitioned by users, and
smallponddistributes these partitions across nodes for parallel processing.
What is 3FS?
3FS, or Fire-Flyer File System, is a high-performance parallel file system also developed by DeepSeek. It's optimized specifically for AI and HPC workloads, offering extremely high throughput and low latency by using SSDs and RDMA networking technology. 3FS is the high-speed, distributed storage backend that smallpond leverages to get it's breakneck performance. 3FS achieves a remarkable read throughput of 6.6 TiB/s on a 180-node cluster, which is significantly higher than many traditional distributed file systems.
How Can I Use It?
To start, same as any other python package, uv pip install smallpond. Remove uv if you like pain.
But to actually get the benefits of smallpond, it'll take much more work and depends largely on your data size and infrastructure:
- Under 10TB:
smallpondis likely unnecessary unless you have very specific distributed computing needs. A single-node DuckDB instance or simpler storage solutions will be simpler and possibly more performant. To be candid, usingsmallpondat a smaller scale, without Ray / 3FS is likely slower than vanilla DuckDB and a good bit more complicated. - 10TB to 1PB:
smallpondbegins to shine. You'd set up a cluster (see below) with several nodes, leveraging 3FS or another fast storage backend to achieve rapid parallel processing. - Over 1PB (Petabyte-Scale):
smallpondand 3FS were explicitly designed to handle massive datasets. At this scale, you'd need to deploy a larger cluster with substantial infrastructure investments.
Deployment typically involves:
- Setting up a compute cluster (AWS EC2, Google Compute Engine, or on-prem).
- Deploying 3FS on nodes with high-performance SSDs and RDMA networking.
- Installing
smallpondvia Python to run distributed DuckDB tasks across your cluster.
Steps #1 and #3 are really easy. Step #2 is very hard. 3FS is new, so there's no guide on how you would set it up on AWS or any other cloud (maybe DeepSeek will offer this?). You could certainly deploy it on bare metal, but you'd be descending into a lower level of DevOps hell.
Note: if you're in the 95% of companies in the under 10TB bucket, you should really try Definite.
I experimented with running smallpond with S3 swapped in for 3FS here, but it's unclear what, if any, performance gains you'd get over scaling up a single node for moderate-sized data.
Is smallpond for me?
tl;dr: probably not.
Whether you'd want to use smallpond depends on several factors:
- Your Data Scale: If your dataset is under 10TB,
smallpondadds unnecessary complexity and overhead. For larger datasets, it provides substantial performance advantages. - Infrastructure Capability:
smallpondand 3FS require significant infrastructure and DevOps expertise. Without a dedicated team experienced in cluster management, this could be challenging. - Analytical Complexity:
smallpondexcels at partition-level parallelism but is less optimized for complex joins. For workloads requiring intricate joins across partitions, performance might be limited.
How Smallpond Works (Under the Hood)
Lazy DAG Execution
Smallpond uses lazy evaluation for operations like map(), filter(), and partial_sql(). It doesn't run these immediately. Instead, it builds a logical execution plan as a directed acyclic graph (DAG), where each operation becomes a node (e.g., SqlEngineNode, HashPartitionNode, DataSourceNode).
Nothing actually happens until you trigger execution explicitly with actions like:
write_parquet()— Writes data to diskto_pandas()— Converts results to a pandas DataFramecompute()— Forces computation explicitlycount()— Counts rowstake()— Retrieves a subset of rows
This lazy evaluation is efficient because it avoids unnecessary computations and optimizes the workflow.
From Logical to Execution Plan
When you finally trigger an action, the logical plan becomes an execution plan made of specific tasks (e.g., SqlEngineTask, HashPartitionTask). These tasks are the actual work units distributed and executed by Ray.
Ray Core and Distribution
Smallpond’s distribution leverages Ray Core at the Python level, using partitions for scalability. Partitioning can be done manually, and Smallpond supports:
- Hash partitioning (based on column values)
- Even partitioning (by files or row counts)
- Random shuffle partitioning
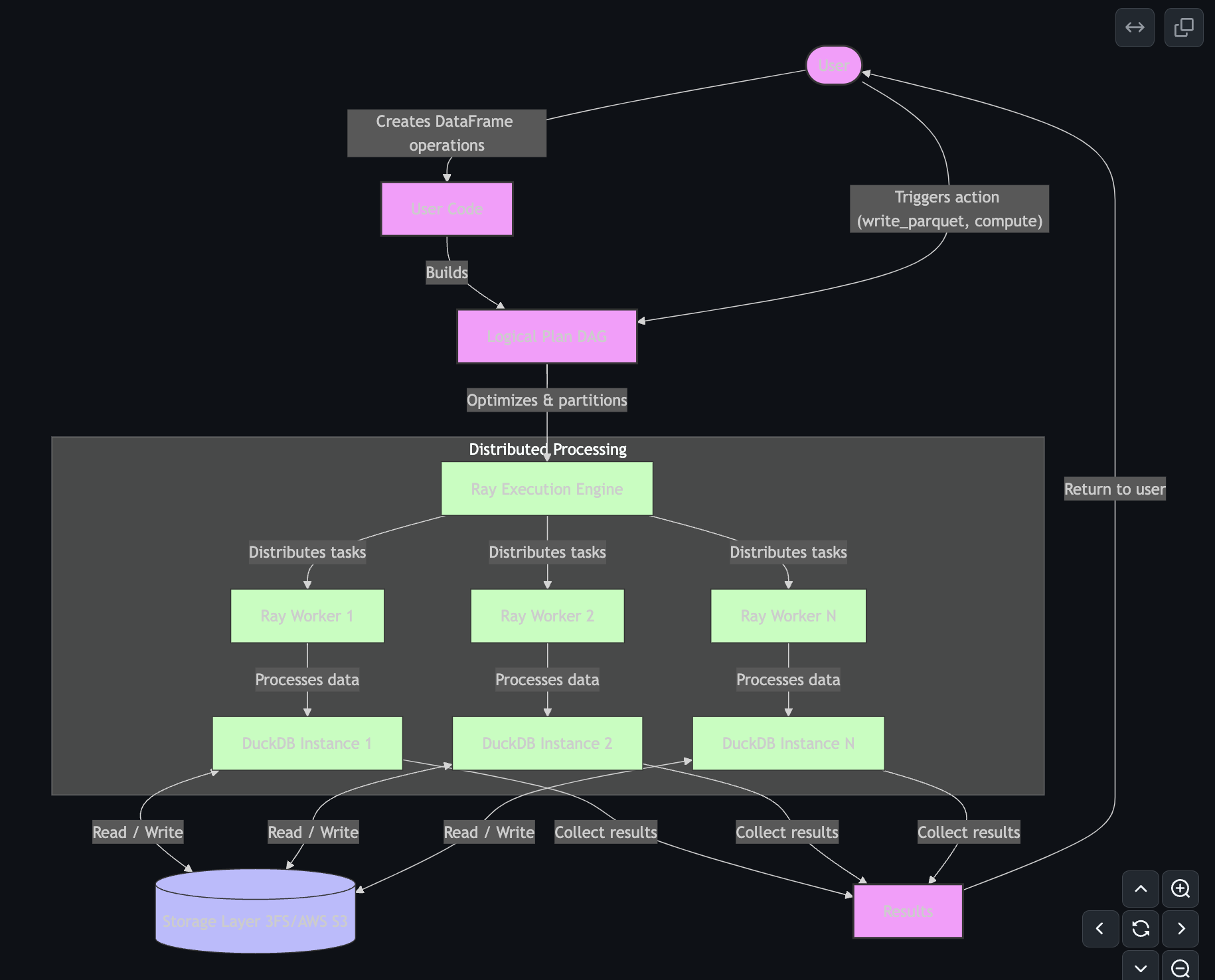
Each partition runs independently within its own Ray task, using DuckDB instances to process SQL queries. This tight integration with Ray emphasizes horizontal scaling (adding more nodes) rather than vertical scaling (larger, more powerful nodes). To use it at scale, you’ll need a Ray cluster. You can run one on your own infrastructure on a cloud provider (e.g. AWS), but if you just want to test this out, it'll be easier to get started with Anyscale (founded by Ray creators).
Conclusion
smallpond and 3FS offer powerful capabilities for scaling DuckDB analytics across large datasets. However, their complexity and infrastructure demands mean they're best suited for scenarios where simpler solutions no longer suffice. If you're managing massive datasets and already have robust DevOps support, smallpond and 3FS could significantly enhance your analytics capabilities. For simpler scenarios, sticking with a single-node DuckDB instance or using managed solutions remains your best option.