Why Databricks paid $1B for a 40 person startup (Tabular)

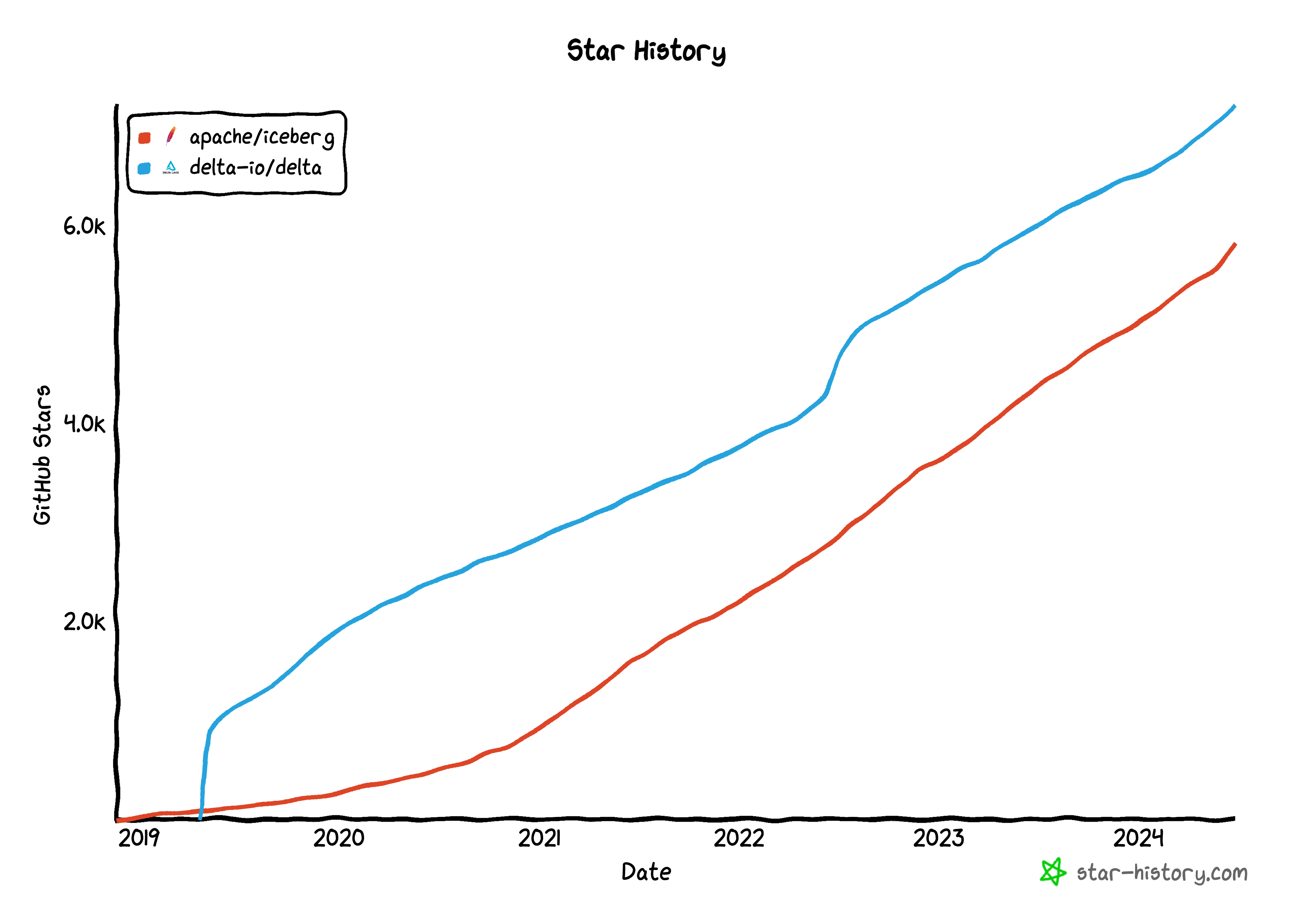
In case you missed it, earlier this month Databricks acquired Tabular, the company behind the open source project Iceberg, for over $1 billion. The acquisition, which was announced during Snowflake’s 2024 Summit conference and amid rumors of Snowflake’s interest in purchasing Tabular, caught many by surprise especially since Databricks already offers a competing product, Delta Lake. So, what is Iceberg, how does it compare to Delta Lake, and what does the project’s future look like post-acquisition?
Iceberg: Bringing CRUD Operations To Your Data Lake
In a world where the volume and variety of data collected by companies is steadily increasing, the importance of data lakes has also grown. Data lakes are centralized repositories that allow companies to store structured and unstructured data for later use such as transforming it in a data warehouse for BI or providing training data for AI models. Due to the varied format and large data size (eg think real-time streaming data from a ride-share app), the data is often stored as raw files in a data lake.
Iceberg, which was originally developed by Netflix, is an open source table format that allows developers to efficiently run CRUD (Create, Read, Update, Delete) operations on files in data lakes, specifically parquet files. In other words, it can make a large set of parquet files feel more like using a SQL database while maintaining parquet’s distinct scaleability and file compression features. Since Iceberg’s inception in 2017, the project has grown quickly in popularity and has been adopted by many large tech companies such as Linkedin, Apple, and Stripe. Tabular, which was founded by the Netflix engineers who created Iceberg, offers a managed service version of Iceberg to customers.
Iceberg vs Delta Lake
Delta Lake is Databrick’s existing product equivalent to Iceberg. Below we discuss how Iceberg and Delta Lake compare to each other across several domains.
Open Source
Both Iceberg and Delta Lake are open sourced under the Apache License and both have meaningful contributions from developers outside of their respective main-company backers (Tabular and Databricks). However despite Delta Lake’s open source status, some have pointed out that certain features available in Databrick’s own Delta Lake implementation are not available or are under-optimized in the OSS version. While it is certainly possible to set up Delta Lake outside of Databricks, some developers have also noted that it can be more complicated to do so relative to setting up Iceberg. Still Delta Lake is used by many outside of Databricks’ platform alongside tools like Trino or Presto.
Here’s a couple relevant threads from HackerNews:

Performance
Across all the benchmarks we could find, Delta Lake is faster than Iceberg for querying, ingesting, and updating data. Several benchmarks comparing open table formats including Delta Lake and Iceberg are linked here and here. While speed isn’t always the most critical factor for all use cases, it is for some and should be taken into consideration when deciding between Delta Lake vs Iceberg. Faster performance may also yield cost savings by reducing runtimes of table operations.
Handling Schema Evolution and Drift
Just like in conventional databases, schema changes are also occasionally needed in data lakes such as altering column names, re-partitioning tables, or even rolling back historical states. Both Iceberg and Delta Lake offer the ability to perform these actions, though Iceberg may have a slight advantage. In Iceberg, most schema and partitioning changes only require changes to the metadata whereas in Delta Lake the same change may require rewriting data.
Additionally, Iceberg also snapshots historical states of a table’s metadata allowing for easy rollback of schema changes or for auditing purposes. Delta Lake offers something similar but uses a log based approach that logs each action performed on a table. While both accomplish the same goal of saving historical schema states, some may find Iceberg’s snapshot methodology easier to use and understand.
Integrations and Ecosystem
Iceberg and Delta Lake by themselves are just an open table format; they still require storage and a query engine. Being a project born out of Databricks, Delta Lake is unsurprisingly tightly integrated with Spark and has built-in optimizations specific to Spark. Delta Lake is also compatible with other query engines such as DuckDB, Trino, Athena, and more. Similarly Iceberg can also work with most of the same query engines that Delta Lake works with including Spark and other data warehouses’ query engines. Pre-Databricks’ acquisition of Tabular, Snowflake had been heavily pushing the use of Snowflake as a query engine for Iceberg (more on that later).
Storage wise both Iceberg and Delta Lake support any type of storage that can store parquet files such as S3 or Google Cloud Storage.
Iceberg’s Future Post Tabular Acquisition
Given that Iceberg is a close competitor to Delta Lake, did Databricks acquire Tabular for the sole purpose of nuking its competition? As intriguing as it might sound, this scenario seems unlikely given that the Iceberg project is open sourced under the Apache Foundation and is implemented by many large tech companies who will continue to use and contribute to the project even if Tabular ceases to exist. Rather we can speculate that Databricks’ acquired Tabular for several reasons:
- Onboarding Iceberg users to Databricks’ ecosystem: by offering support for Iceberg, Databricks may be able to better attract users to its platform and cross-sell other products. This move could also lead to a larger user base and increased market share.
- Influencing the development of Iceberg: with the main contributors and creators of Iceberg now at Databricks, Databricks can better steer the evolution of Iceberg to align with its ecosystem of products.
- Strategic move to beat out Snowflake from acquiring and building out a data lake competitor: though Snowflake is an established player in the data warehouse space, it is a relative newcomer to the data lake game. Snowflake’s support for Snowflake compute + Iceberg along with its bid for Tabular revealed it was looking to get more serious about building its own data lake product. By acquiring Tabular first, Databricks effectively preempted Snowflake's efforts to strengthen its position in the data lake market.
A billion dollar acquisition for a 3-year old startup is certainly noteworthy and we are eager to see what the future holds for both Databricks and Iceberg. Iceberg is a key component of what we’re building here at Definite, so we’re hoping the acquisition leads to a better, open table format.
Data doesn’t need to be so hard
Get the new standard in analytics. Sign up below or get in touch and we’ll set you up in under 30 minutes.