Running Iceberg and Serverless DuckDB in Google Cloud

In a previous post we provided examples on how to query Iceberg tables with DuckDB on a local machine. In this post, our goal is to replicate those same examples in a cloud environment. More specifically, we show how the following can be set up on Google Cloud:
- A Postgres instance serving as the Iceberg catalog
- Google Cloud Storage for storing Iceberg metadata and tables (parquet files)
- A cloud VM for running DuckDB queries on Iceberg
If you follow along, hopefully you’ll have some ideas on how to build a "Pretty Good and Cheap Data Lake™" at the end. Let’s dive in!
Google Cloud Postgres and Storage Setup
Postgres
To provision a new Postgres instance in Google Cloud:
- Go to SQL instances in the Google Cloud console
- Click
Create Instanceand select PostgreSQL - On the next page select the PostgreSQL version you want to use, a name and password for your instance, and what region or availability you want for the instance. You can also customize the machine and storage configurations in the drop downs below. Click Create Instance to finish.
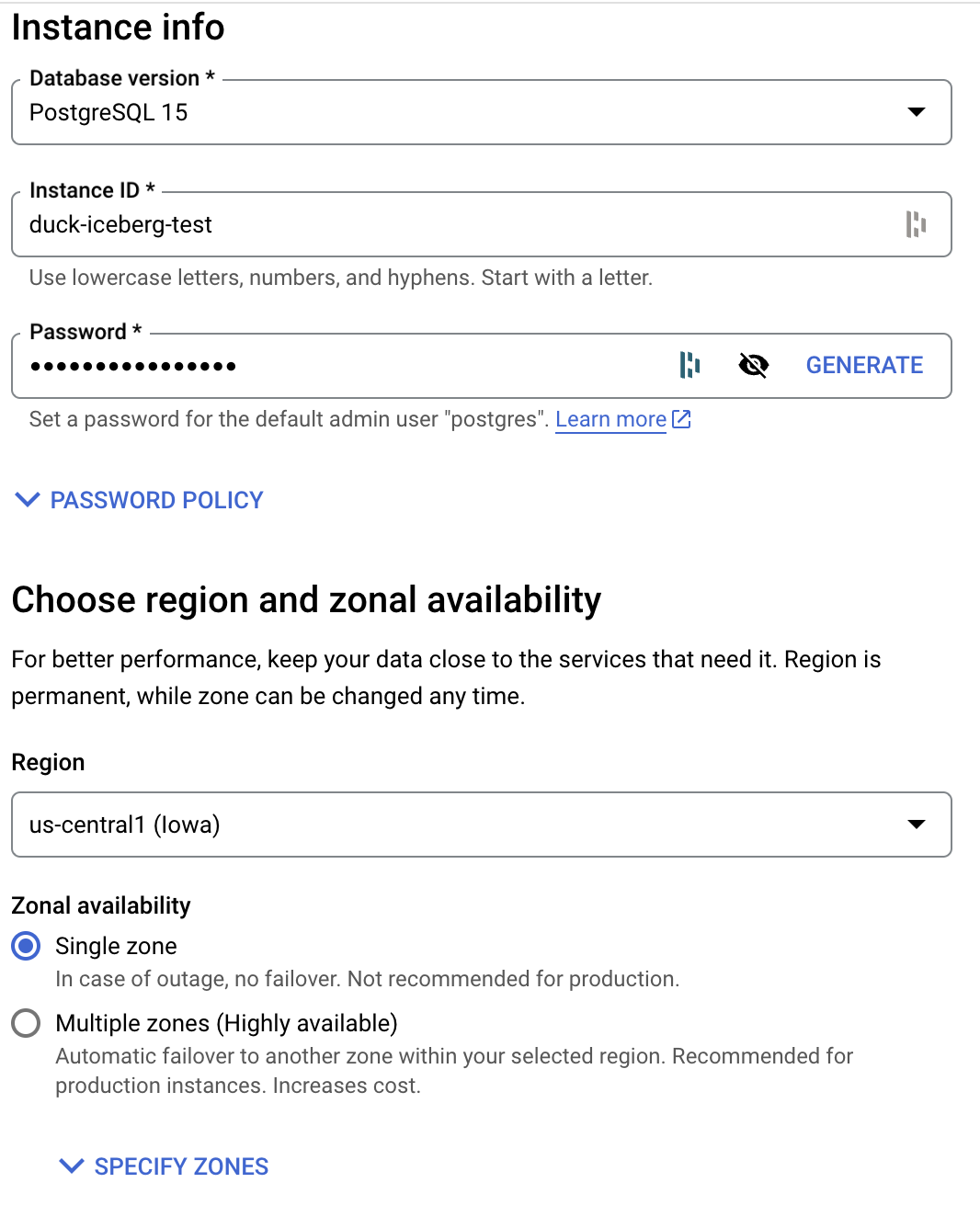
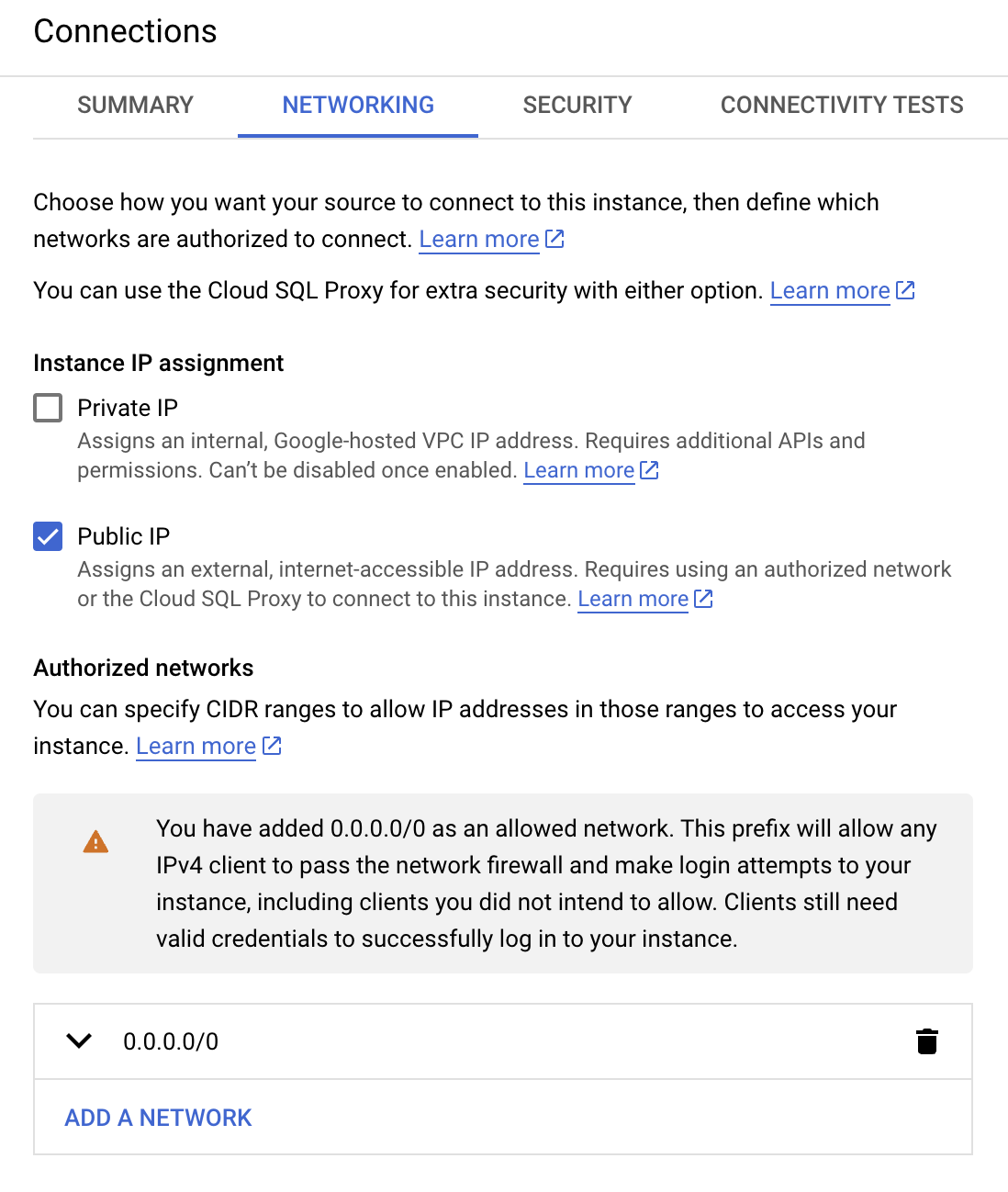
- Once your instance is up and running, click on Connections in the left sidebar menu, then select Networking. For demo purposes we will make the instance available to all IP addresses so select Public IP and add 0.0.0.0/0 to the list of authorized networks:
 Your Postgres connection URI should look something like:
Your Postgres connection URI should look something like:
postgresql://<USER>:<PASSWORD>@<HOST>:5432/postgres
USERis the user you created in step 2 (postgresby default)PASSWORDis the password you created in step 2 (make sure it is percent encoded)HOSTis the IP address of your instance which you can find on theOverviewmenu underPublic IP address
Save the URI for use later.
Setting Up Cloud Storage
- Go to Cloud Storage in the console and click
CREATEin the top menu - Create a name for you bucket, select storage region, and any other configurations on the next page (most defaults work, selecting a single region will be cheaper). Click
Createonce finished: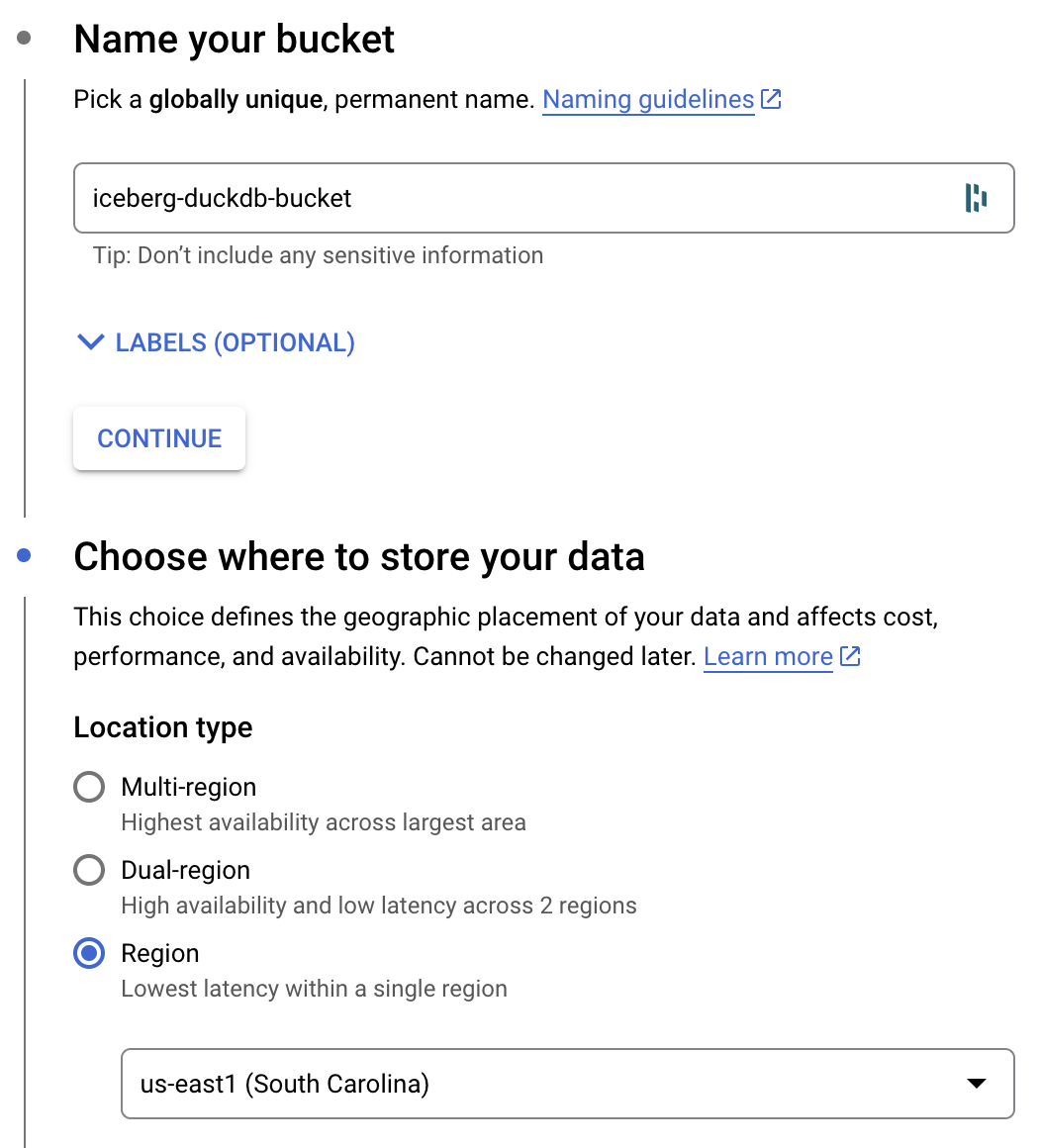
Create HMAC Key and Secret Key
An HMAC key and HMAC secret key are needed to access objects in Cloud storage. These will later be used by DuckDB to access Iceberg tables stored in GCS (Google Cloud Storage). To create the keys follow these instructions. Make sure you save these keys, we will use them later!
If you want to create a new service account for the keys we suggest giving it the minimum permissions of Storage Object Viewer so that it can be used to read data from GCS.
Creating The Catalog
Now that we have Postgres and cloud storage set up we can create the catalog. To do this we will use PyIceberg, a Python library for interacting with Iceberg. The following code registers a name space called taxi (we will use the NYC taxi data set again) in the Postgres catalog. The catalog will eventually contain pointers to where the data and metadata are saved in GCS:
from pyiceberg.catalog.sql import SqlCatalog
# create Iceberg catalog using Postgres and GCS
catalog_name = "demo_iceberg"
catalog_uri = "<YOUR_POSTGRES_URI>" #replace with Postgres URI
warehouse_path = "gs://<YOUR_BUCKET>" #replace with bucket name you created in GCS
catalog = SqlCatalog(
catalog_name,
**{
"uri": catalog_uri,
"warehouse": warehouse_path,
},
)
# create a namespace for Iceberg
name_space = 'taxi'
try:
catalog.create_namespace(name_space)
except Exception as e:
print(e)
If you examine the contents of the Postgres database, you should see this (open the database in Cloud SQL, select your instance, then select Studio in the left side bar which opens a SQL editor):
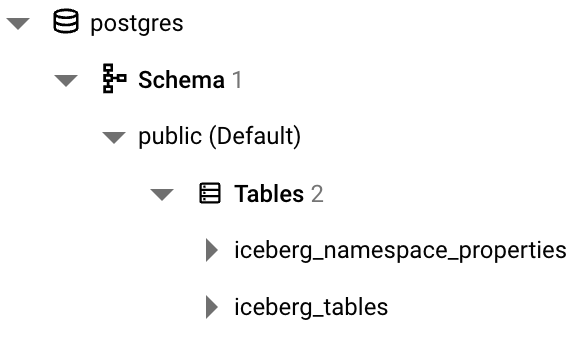
iceberg_namespace_properties will contain one row detailing the taxi namespace we just created whereas iceberg_tables will be empty since we haven’t created any Iceberg tables yet.
Loading Data Into Iceberg
Now that we have the Postgres catalog setup and pointing to our cloud storage bucket, we can create Iceberg tables and start loading data. This part will be largely similar to the previous post in which we loaded some data from the NYC taxi data set.
First we get the data from the NYC taxi site and convert it to PyArrow format:
import duckdb
import pyarrow as pa
# get Q2 2023 to through april 2024 (latest available data)
trips_ls = []
months = [
'2023-04',
'2023-05',
'2023-06',
'2023-07',
'2023-08',
'2023-09',
'2023-10',
'2023-11',
'2023-12',
'2024-01',
'2024-02',
'2024-03',
'2024-04'
]
for month in months:
table_path = f'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_{month}.parquet'
# NOTE: this initial data read doesn't require Duckdb, something like pandas works as well
table = duckdb.sql(f"SELECT * FROM '{table_path}'").arrow()
trips_ls.append(table)
# concatenate all trips tables
trips = pa.concat_tables(trips_ls)
print("Rows in trips: ",trips.num_rows)
# get location zone mapping
zones = duckdb.sql("SELECT * FROM 'https://d37ci6vzurychx.cloudfront.net/misc/taxi_zone_lookup.csv'").arrow()
print("Rows in zones: ",zones.num_rows)
Note: we use DuckDB for the initial data read from the taxi site but it’s not required, something like pandas would also work.
Before creating the Iceberg tables, we also define a helper function that ensures that every table’s catalog and metadata are properly synced. This is to address the Github issue mentioned **here.** Readers of our previous post may notice that we’ve updated this function from last time; previously it was two functions and now also supports GCS files:
import gcsfs
def add_version_hint(iceberg_table):
"""
Adds version hint file to Iceberg table metadata
Addresses issue mentioned here: https://github.com/duckdb/duckdb-iceberg/issues/29
Determines if Iceberg table is in local file system or in GCS
"""
metadata_location = iceberg_table.metadata_location
protocol = metadata_location.split(":")[0]
if protocol == "file":
metadata_location = metadata_location[7:]
elif protocol == "gs":
metadata_location = metadata_location[5:]
else:
print(f"Unsupported metadata location: {metadata_location}")
return
metadata_dir = os.path.dirname(metadata_location)
new_metadata_file = os.path.join(metadata_dir, "v1.metadata.json")
version_hint_file = os.path.join(metadata_dir, "version-hint.text")
if protocol == "file":
shutil.copy(metadata_location, new_metadata_file)
with open(version_hint_file, "w") as f:
f.write("1")
elif protocol == "gs":
fs = gcsfs.GCSFileSystem()
fs.copy(metadata_location, new_metadata_file)
with fs.open(version_hint_file, "w") as f:
f.write("1")
print(f"Copied metadata file to {new_metadata_file}")
print(f"Created {version_hint_file} with content '1'")
Ok let’s create the Iceberg tables and load the taxi data. The code below registers the Iceberg tables in the Postgres catalog, loads the data and metadata into the GCS bucket, and then adds the version hint files for each table into GCS:
# add tables to iceberg catalog and load data into GCS
for table, table_name in [
(trips, "trips"),
(zones, "zones"),
]:
# create the iceberg table
iceberg_table = catalog.create_table(
f"{name_space}.{table_name}",
schema=table.schema,
)
# add data to iceberg table in GCS
iceberg_table.append(table)
# copy catalog version hint metadata into GCS
add_version_hint(iceberg_table)
print(f"Created {table_name}, {table.num_rows} rows")
Note: you may need to authenticate your Google Cloud account first by running: gcloud auth login . More info on Google Cloud authentication can be found here.
Let’s take a peek at what the above code just did. If we go into the iceberg_tables table in Postgres catalog we should see that two tables were created. Again, you can use the Studio functionality in Cloud SQL to query this:
 We can see that we created a
We can see that we created a trips and a zones table. Each table also has a metadata_location which points to a location in GCS where the metadata for each table is saved. In our case the metadata for the trips table is saved here in GCS:
gs://def-blog-bucket/duck-iceberg-blog/taxi.db/trips/metadata/00001-f3c15f5d-ec6b-467c-8361-30904988d0e3.metadata.json
Let’s head over to GCS to examine whats in there. In the def-blog-bucket/duck-iceberg-blog/taxi.db/trips directory we see two folders:
 Within the metadata folder lies our metadata file which was referenced in the Postgres catalog. Without getting too much into the weeds, this metadata file contains important information for the
Within the metadata folder lies our metadata file which was referenced in the Postgres catalog. Without getting too much into the weeds, this metadata file contains important information for the trips table such as where the data is, how the table is partitioned, etc. For a deeper understanding of how the metadata file works this blog post is a great explainer.
Within the data folder is our actual data saved as parquet files. The metadata file will instruct the query engine where and how to read data from this folder:
Querying With DuckDB
With our Iceberg tables created and data loaded we can now query them. We demonstrate two ways to do this:
- Using DuckDB to locally query remote Iceberg tables in cloud storage
- Running DuckDB on a cloud VM to query remote Iceberg tables in cloud storage
Local DuckDB
Using a local DuckDB setup to query our cloud hosted Iceberg tables is similar to the approach shown in our previous post except we point DuckDB at cloud storage instead of local files. To give our local DuckDB access to our GCS bucket we need to use our HMAC key and secret key created in the cloud storage set up stage.
import duckdb
con = duckdb.connect(database=':memory:', read_only=False)
# use HMAC credentials to connect to GCS
setup_sql = '''
INSTALL iceberg;
LOAD iceberg;
CREATE SECRET (
TYPE GCS,
KEY_ID '<YOUR_HMAC_KEY>',
SECRET '<YOUR_HMAC_SECRET>'
);
'''
con.execute(setup_sql)
Same as in the previous post we create a taxi schema and views of the trips and zones tables in DuckDB:
warehouse_path = "gs://YOUR_BUCKET"
name_space = 'taxi'
# create the schema and views of iceberg tables in duckdb
database_path = f'{warehouse_path}/{name_space}.db'
create_view_sql = f'''
CREATE SCHEMA IF NOT EXISTS taxi;
CREATE VIEW taxi.trips AS
SELECT * FROM iceberg_scan('{database_path}/trips', allow_moved_paths = true);
CREATE VIEW taxi.zones AS
SELECT * FROM iceberg_scan('{database_path}/zones', allow_moved_paths = true);
'''
con.execute(create_view_sql)
We can now run queries against the Iceberg tables in GCS using DuckDB. For example this query retrieves monthly aggregated trip statistics:
sql = f'''
select
date_trunc('month', tpep_pickup_datetime) as month,
avg(passenger_count) as avg_passenger_count,
avg(trip_distance) as avg_trip_distance,
sum(trip_distance) as total_trip_distance,
avg(total_amount) as avg_total_amount,
sum(total_amount) as total_amount,
count(*) as total_trips
from taxi.trips
-- some data pre and post our target date range is in the dataset, so we filter it out
where tpep_pickup_datetime between '2023-04-01' and '2024-05-01'
group by 1
order by 1
'''
%time res = con.execute(sql)
res.fetchdf()
An example notebook of setting up the catalog, loading data, and querying Iceberg tables with a local DuckDB instance can be found here.
Deploy DuckDB In A Cloud VM
To run DuckDB in a VM we will deploy a Flask app with an endpoint that executes DuckDB sql queries against objects in cloud storage and returns the results. The file structure of our app looks like this:
deploy_duckdb
├── config.py
├── main.py
├── requirements.txt
└── build_cloud_run.sh
The contents of each file can be found in the repo here. For this post we will briefly go over main.py and config.py.
# main.py
import duckdb
from flask import Flask, request, jsonify
from google.cloud import secretmanager
import config
app = Flask(__name__)
# gets secrets from google secret manager
def get_secret(secret_name: str, project_id: str):
client = secretmanager.SecretManagerServiceClient()
secret = client.access_secret_version(
name=f"projects/{project_id}/secrets/{secret_name}/versions/latest"
)
return secret.payload.data.decode("utf-8")
def init_duckdb_connection():
hmac_key = config.HMAC_KEY
hmac_secret = get_secret(config.HMAC_SECRET_KEY_NAME, config.PROJECT_ID)
con = duckdb.connect()
setup_sql = f"""
INSTALL iceberg;
LOAD iceberg;
INSTALL httpfs;
LOAD httpfs;
CREATE SECRET (
TYPE GCS,
KEY_ID '{hmac_key}',
SECRET '{hmac_secret}'
);
"""
con.execute(setup_sql)
return con
# global duckdb connection
duckdb_conn = init_duckdb_connection()
@app.route("/query", methods=["POST"])
def query_iceberg():
try:
query = request.args.get("query")
if not query:
return jsonify({"error": "Query parameter 'query' is required"}), 400
result = duckdb_conn.execute(query).fetchall()
return jsonify({"result": result}), 200
except Exception as e:
return jsonify({"error": str(e)}), 500
if __name__ == "__main__":
app.run(debug=True)
Notice that init_duckdb_connection() is used to initialize a DuckDB database upon app creation that has access to the cloud storage buckets and can be called upon for queries. Within init_duckdb_connection() there is a request to get the HMAC secret key from Google Secrets Manager. We configure the project id and secret name in config.py like so:
PROJECT_ID = "<YOUR_PROJECT_ID>"
HMAC_KEY = "<YOUR_HMAC_KEY>"
HMAC_SECRET_KEY_NAME = "<YOUR_HMAC_SECRET_KEY_NAME>"
You will want to add your HMAC secret to Secrets Manager. Make sure the name of the secret matches the name in config.py. See here on how to add secrets.
Once the config file and secrets are added, we can deploy the app to a Cloud Run VM using:
bash build_cloud_run.sh
Once the app is deployed, the url of the app can be found in the Cloud Run UI here:
 With the app url we can pass SQL queries to the query endpoint and DuckDB will query our Iceberg tables in GCS:
With the app url we can pass SQL queries to the query endpoint and DuckDB will query our Iceberg tables in GCS:
import requests
# create the schema and views of iceberg tables in duckdb
warehouse_path = "gs://YOUR_BUCKET"
name_space = 'taxi'
database_path = f'{warehouse_path}/{name_space}.db'
url = '<CLOUD_RUN_URL>/query'
create_view_sql = f'''
CREATE SCHEMA IF NOT EXISTS taxi;
CREATE OR REPLACE VIEW taxi.trips AS
SELECT * FROM iceberg_scan('{database_path}/trips', allow_moved_paths = true);
CREATE OR REPLACE VIEW taxi.zones AS
SELECT * FROM iceberg_scan('{database_path}/zones', allow_moved_paths = true);
'''
query = {
"query": create_view_sql
}
response = requests.post(url, params=query)
# Query Total Trips By Pickup and Drop-off Borough:
sql = f'''
select
starting_zone.Borough as pickup_borough,
ending_zone.Borough as dropoff_borough,
count(*) as trip_count
from
taxi.trips as trips
left join taxi.zones as starting_zone
on trips.PULocationID = starting_zone.LocationID
left join taxi.zones as ending_zone
on trips.DOLocationID = ending_zone.LocationID
group by 1, 2
order by 1 asc, 3 desc
limit 20
'''
query = {
"query": sql
}
response = requests.post(url, params=query)
response.json()
The last query above will return results in json format like so:
{'result': [['Bronx', 'Bronx', 38900],
['Bronx', 'Manhattan', 33779],
['Bronx', 'Queens', 7179],
['Bronx', 'Brooklyn', 6943],
['Bronx', 'N/A', 522],
['Bronx', 'Unknown', 231],
['Bronx', 'Staten Island', 163],
['Bronx', 'EWR', 35],
['Brooklyn', 'Brooklyn', 181514],
['Brooklyn', 'Manhattan', 130742],
['Brooklyn', 'Queens', 43224],
['Brooklyn', 'Bronx', 6967],
['Brooklyn', 'N/A', 1002],
['Brooklyn', 'EWR', 922],
['Brooklyn', 'Unknown', 896],
['Brooklyn', 'Staten Island', 643],
['EWR', 'EWR', 4710],
['EWR', 'Unknown', 237],
['EWR', 'N/A', 205],
['EWR', 'Manhattan', 129]]}
It’s important to note that the app isn’t specific to Iceberg. It can query any parquet or csv file in cloud storage using DuckDB. For example if we wanted to query a raw parquet file in a different bucket we could do it like this
import requests
sql = f'''
select
count(*)
from read_parquet('gs://<OTHER_BUCKET>/some_data.parquet');
'''
url = '<CLOUD_RUN_URL>/query'
query = {
"query": sql
}
response = requests.post(url, params=query)
response.json()
Things To Note
When this post was written, DuckDB could only read Iceberg tables, so CRUD operations such as loading data had to be handled by some other tool (e.g. PyIceberg). That has since changed: DuckDB's Iceberg extension added write support in v1.4.0 (INSERT) with UPDATE and DELETE for Iceberg v2 tables following in v1.4.2. Note that attaching a DuckDB database file stored in GCS is still read-only. Either way, views of Iceberg tables can be created and saved within DuckDB allowing users to define and persist transformation logic without modifying the underlying data. Newer DuckDB versions can also attach an Iceberg REST catalog directly, so the manual catalog/metadata-sync helper shown earlier in this post isn't required in those setups.
When this post was written, predicate pushdown support for querying Iceberg was still being developed; that issue has since been resolved. DuckDB and Iceberg have continued to improve and work better together over time.
In our example app, DuckDB only persists so long as the VM is still running. When the VM shuts down, the DuckDB connection also terminates and any views created do not persist. To persist the views we can run DuckDB on a VM with a persistent disk attached to it which would allow us to save and read .duckdb files directly from the disk.
Lastly, loading data in a more production-ready way was not something we touched upon in this post; we just loaded the static NYC taxi data set for demo purposes. In a real production setting there would be a process to ingest data into Iceberg tables which was not in the scope of this post. An example of this could be a custom Meltano Iceberg target, which we built and open sourced, that loads data from a variety of sources into Iceberg.
Conclusion
Though relatively high-level, this post hopefully provides some ideas on how to use Iceberg and DuckDB in a cloud setting. While we used Google Cloud, the same can be done on equivalent products (managed Postgres, GCS, Cloud Run) in AWS or Azure. At Definite, we’ve been building a data stack around open source tools like Iceberg and DuckDB; if you would like to try out what we’ve built please check us out at https://www.definite.app/.
All code for this post can be found here.